gImageReader — простой Python / GTK (Gnome) графический интерфейс (GUI) к консольному приложению для распознавания текста Tesseract (frontend to tesseract-ocr).


Tesseract — консольное приложение для оптического распознавания текста. Разработкой приложения, с 1985 по 1995 год, занималась компания Hewlett-Packard (HP). После 2005 года разработка Tesseract была заморожена на 10 лет. Но в 2005 году исходные коды приложения были открыты и дальнейшую разработку возглавила компания Google.
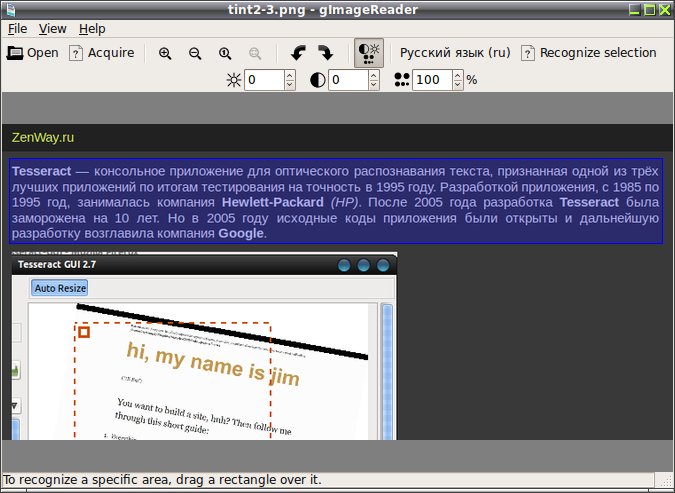

Система оптического распознавания символов (текста) Tesseract, обычно используется для конвертации сканированных книг и документов в электронный вид, поддерживает распознавание множества языков (включая русский, с версии 3.0), имеется поддержка UTF-8 (кодировка реализующая представление Юникода).
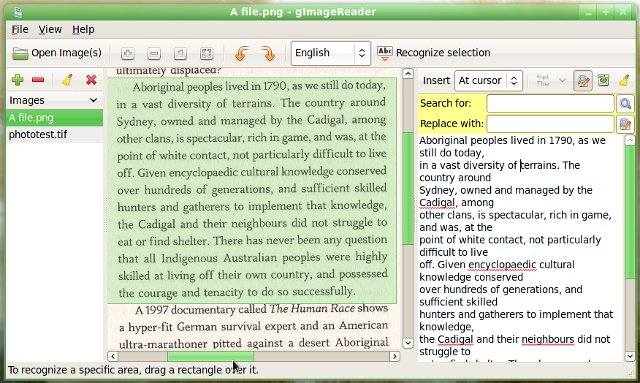
Открываемые в gImageReader для распознавания изображения могут быть монохромными (черно-белыми), серыми и/или цветными. Изображения могут быть форматов PNG или JPG, хотя для более качественного распознавания текста рекомендуется преобразовать изображение в формат хранения растровых изображений TIFF (Tagged Image File Format).
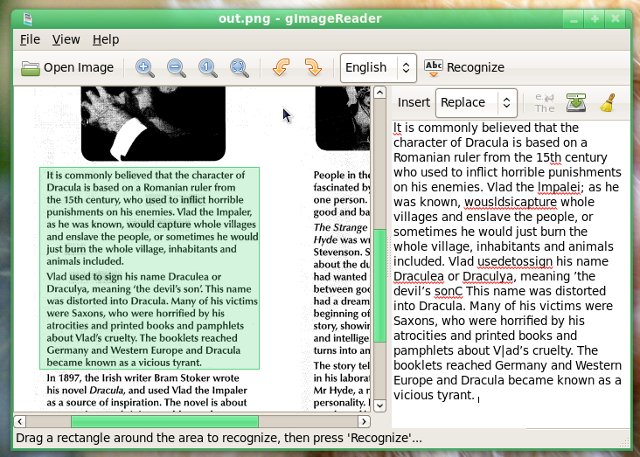

gImageReader даёт возможность повысить яркость и контрастность изображения, изменить угол наклона (на оригинальном изображении изменения не отражаются). Распознаваться может как текст на всём изображении, так и текст только выделенного участка изображения.
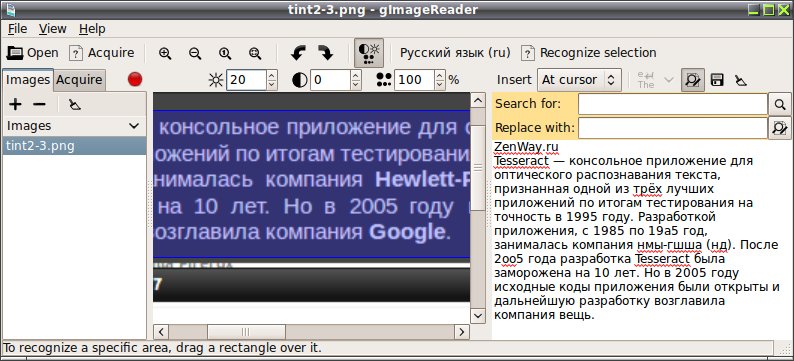
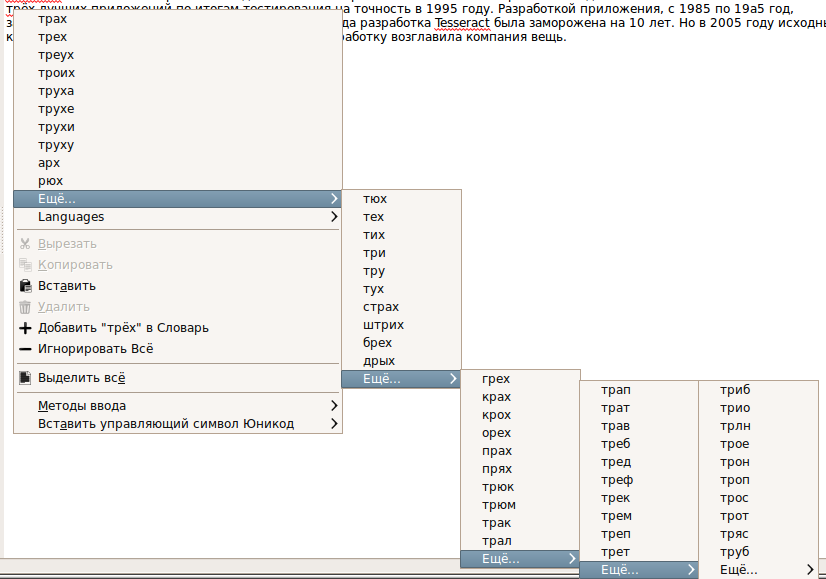
gImageReader в распознанном тексте позволяет редактировать текстовое содержимое, проводит проверку орфографии (используется Aspell, можно добавить русский словарь из OpenOffice) и сохраняет распознанный текст в файле формата TXT.
Лицензия: GNU General Public License v3.0 (GPLv3)

Комментариев: 9 RSS
1panas05-09-2011 20:47
а как добавить русский?
что то у меня в предпочитаемых языках можно выбрать только английский в разных интерпретациях :(
2posixru05-09-2011 21:10
Tesseract какая версия стоит? Русский доступен только с версии 3.0, а много где в репах ещё лежит tesseract-2.01 потому так и получается! Ну надо освежить его до 3.0 или просто в: /usr/local/share/tessdata/ положить распакованный из архива rus.traineddata скачанный с сайта проекта.
3panas05-09-2011 21:11
дико извиняюсь :)
подключил репозиторий: deb //ppa.launchpad.net/alex-p/notesalexp-natty/ubuntu natty main
поставил Tesseract 3.00 и русский tesseract-ocr-russian
4posixru05-09-2011 21:42
Так даже проще! :)))
5panas06-09-2011 19:07
но вот вопрос, он может распознавать не просто английский или русский, а русско-английский, т.е. многоязычный текст? и как это осуществить?
6posixru06-09-2011 20:18
Распознавание смешанного текста (русско-английский и пр...) в этом интерфейсе я не нашел как сделать, он или оно или другое...
А сразу это реализовано в интерфейсах:
//zenway.ru/page/yagf
//zenway.ru/page/cuneiform-qt
Можно ещё для общей информации посмотреть эти:
//zenway.ru/page/ocrfeeder
//zenway.ru/page/gocr
Ну и если не боимся консоли то можно использовать и этого:
//zenway.ru/page/abbyy-finereader-for-linux
7panas08-09-2011 21:33
спасибо :)
про Cuneiform слышал, распознаёт она неплохо, но вот нет возможности распознать только выделенный текст.. но оказывается есть YAGF..
поздновато я на ваш сайт наткнулся, но теперь буду постоянным читателем..
всё, ушёл пробовать
8Андрей03-04-2012 13:56
"Распознавание смешанного текста (русско-английский и пр...)" зависит не от программы графического интерфейса (gImageReader, YAGF, OCRFeeder), а от системы распознавания (CuneiForm, Tesseract). На данный момент распознавать русско-английский текст может только CuneiForm. Наберите в терминале
отобразится следующее:ruseng - и есть языковой модуль для смешанного алфавита. Других сочетаний языков больше нет нигде (естественно, все утверждения относятся к свободному ПО).9posixru03-04-2012 23:55
Вы можете войти под своим логином или зарегистрироваться на сайте.