
Мощная графическая оболочка для нескольких OCR приложений.

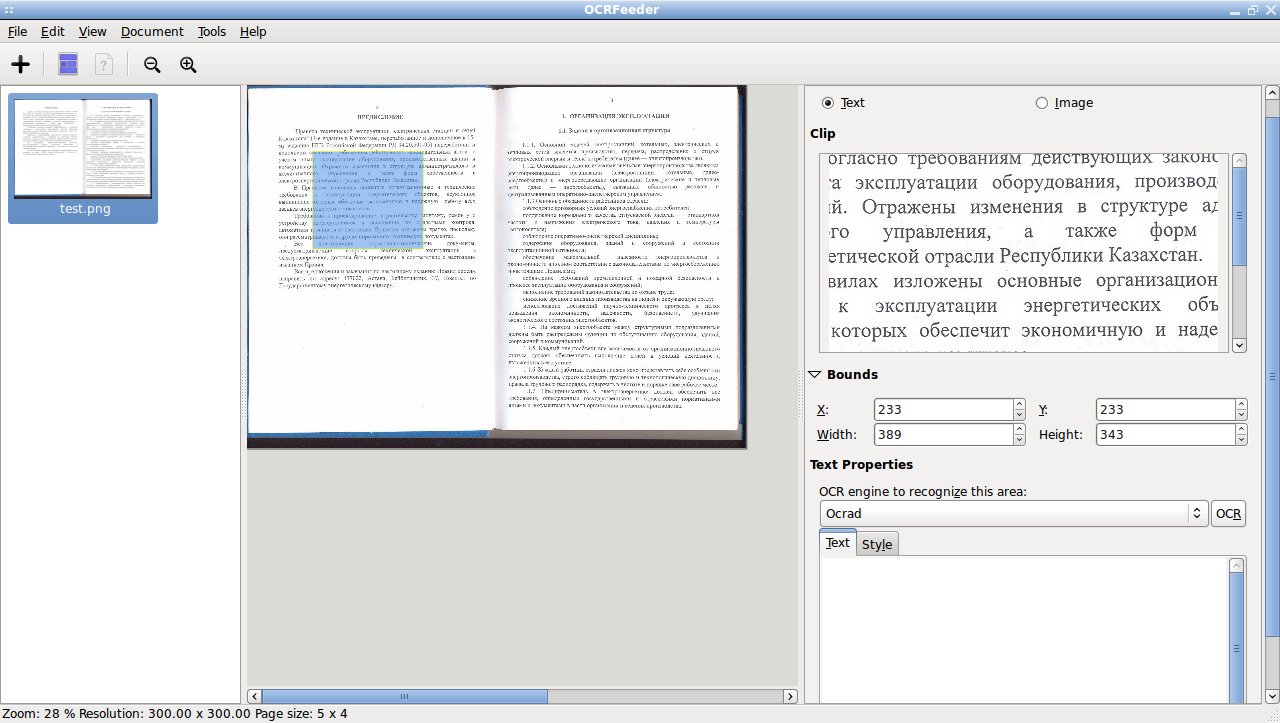
OCRFeeder – удобный Python / GTK+ графический интерфейс к нескольким консольным OCR (optical character recognition) приложениям.
OCR (optical character recognition) — система оптического распознавания символов (текста) используемая для конвертации сканированных книг и документов в электронный вид.
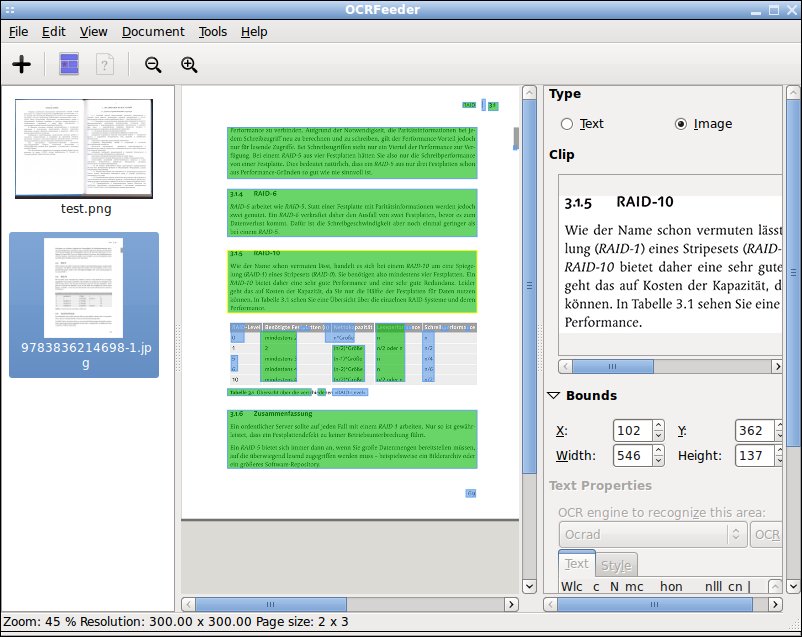
При использовании системы анализа структуры изображения автоматически определяется графическое и текстовое содержимое. Производится оптическое распознавание текста документа, сохраняя его в файл формат которого позволяет редактировать текстовое содержимое.

Разработка OCRFeeder начата как магистерская диссертация по "Прикладной информатике" программистом Joaquim Rocha. В дальнейшем приложение вошло в состав GNOME Project.

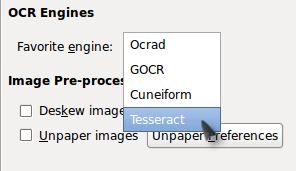
OCRFeeder автоматически определяет наличие инсталлированных в системе OCR приложений, а именно CuneiForm, GOCR, Ocrad, Tesseract используя их в качестве "движка", а для распознания структуры документа применяется собственный алгоритм.

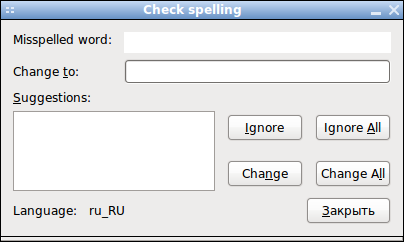
Для поддержки распознавания языков в настройках каждой системы распознавания, CuneiForm, GOCR, Ocrad и Tesseract, необходимо добавить аргумент соответствующий этому языку.
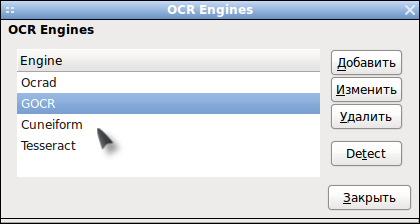
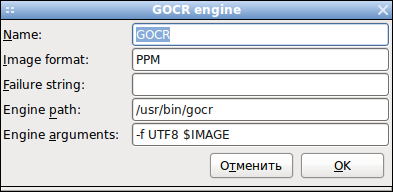
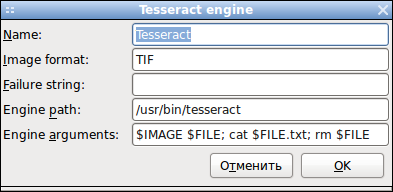
Например для корректного распознавания текстов на русском необходимо добавить "-l rus", а для правильной проверки русской орфографии помечать распознаваемый текст как русский.
В OCRFeeder можно импортировать данные как из графических файлов, множества популярных форматов (JPEG, PNG, BMP, TIFF, GIF, PNM, PPM, PBM и прочих...), из файла PDF, а так же поддерживается захват изображения непосредственно от устройства сканирования. Изображения так же могут быть добавлены простым перетаскиванием из файлового менеджера, на окно приложения (функция drag-and-drop) или из контекстного меню (интеграция с Nautilus).

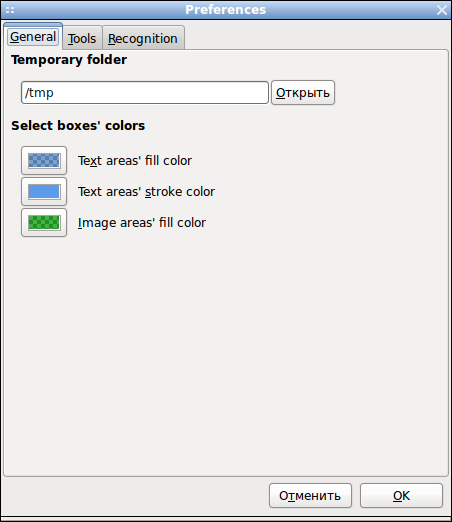
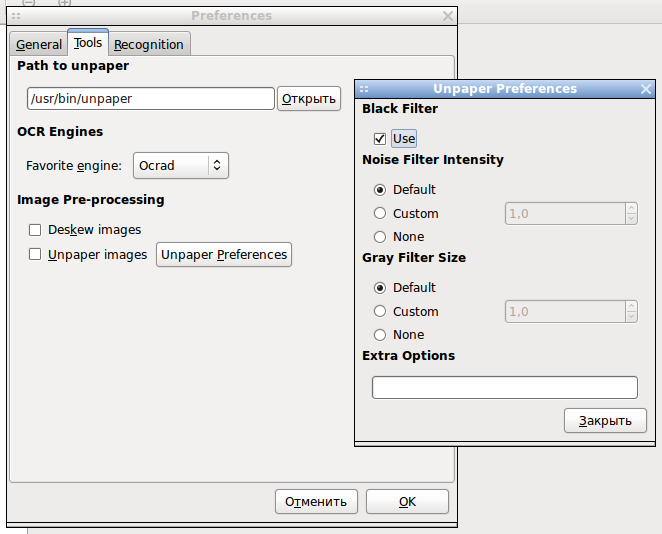
OCRFeeder позволяет очистить исходное изображение (без коррекции оригинала), в открытом изображении задать или изменить границы зон распознавания, выбрать наиболее подходящий для конкретного документа "движок" распознавания символов.
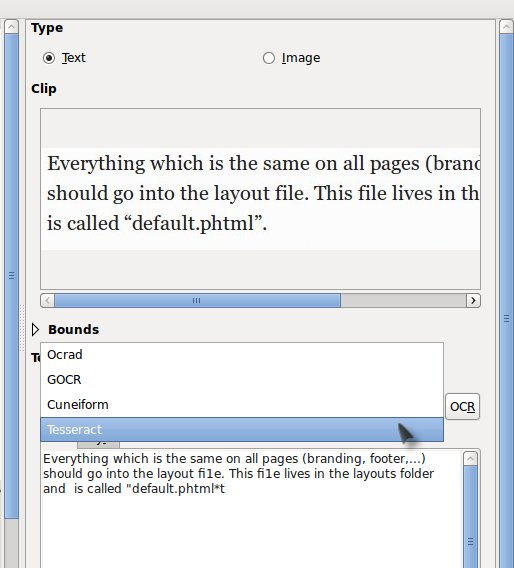
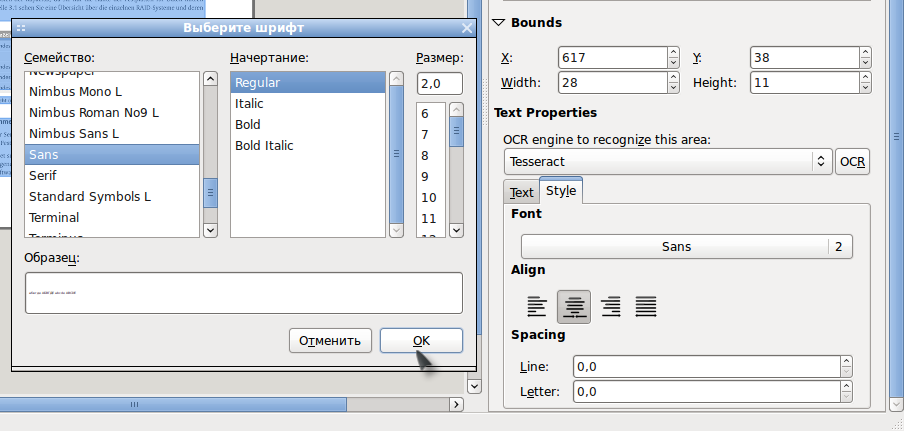
В OCRFeeder имеется возможность коррекции не распознанных символов, настроить стили параграфов, применить проверку орфографии в распознанном тексте с помощью aspell (libaspell) и выбрать шрифт для сохраняемых документов.

Основным форматом для сохранения результатов распознавания в OCRFeeder является ODT (OpenDocument Format). Но так же текст может быть сохранён в обычном текстовом формате TXT, или в HTML.
Хоть OCRFeeder и разрабатывается как приложение с графическим интерфейсом (GUI), но имеется возможность работы и из командной строки (ocrfeeder-cli). Это может оказаться полезным для автоматической пакетной обработки документов (используя "движок" определённый в настройках основным).
Лицензия: GNU GPL v3
Комментариев: 8 RSS
1Владимир Юрганов19-05-2011 12:36
мне интересно, откуда вы эту версию скачали.
на оф. сайте - последняя это 0.6.6
а там нет кнопочки сканировать. и мою kuneiform отказывается видеть
2vovans19-05-2011 15:01
//ftp.gnome.org/pub/GNOME/sources/ocrfeeder/0.7/
3Владимир Юрганов25-05-2011 15:50
спасибо.
но чё то не смог скопилирировать
4Алекс05-06-2011 15:59
Куда писать "l rus"???, можно на скрин это вывести, а то ничего не помогает с русским текстом...
5posixru05-06-2011 21:28
//zenway.ru/uploads/04_11/mini/ocrfeeder_020.png
В строке "Engine arguments", вписывается:
-f -l rus UTF8 $IMAGE
И для других почти так же, но аргумент везде ставится перед $IMAGE Просто -l rus или -l rus UTF8
Всё должно работать, я пробовал распознавать с пару десятков сканов документов, на нескольких языках (на русском в том числе), из четырёх движков один/два вполне сносно распознавали текст.
6juve23-06-2011 06:47
госопда, а как распознать мультиязычный текст?
пойдет ли аргумент типа -l rus,eng UTF8
7juve23-06-2011 06:54
Владимир Юрганов пишет
с аргументом "-l rus UTF8" cuneiform распознает прилично
осталось мультиязычность добавить )
8Андрей02-04-2012 11:31
Если используется Cuineform, то эта система может распознавать одновременно только русский алфавит с английским, для этого используется параметр
Буквенные обозначения языков можно узнать, набрав в терминале:Вы можете войти под своим логином или зарегистрироваться на сайте.